Food for your brain: news.ycombinator.com
It's better than heise.de .
Tried a lot of different beans here in Berlin. These are the best: "African Queen" by Impala Coffee
A house blend. Dark roasted, with a hint of caramel.
Get it fresh.
When I listen to music, I mostly use my atom-board home server as a player and of course I want to control it from remote. But I don't like those complicated networked sound architectures (mpd, pulseaudio, jack). I just want to ssh on the box, put some music on the playlist and disconnect.
To do that, you obviously need a player that works from the command line. So far I used herrie. It has done a great job and I still like its simple interface.
But recently I wanted to upgrade from the onboard Intel HD audio to a solution with optical out. As I will need the single PCI slot for a gigabit ethernet card, I bought a USB soundcard, a "Creative SoundBlaster X-Fi 5.1 Sourround Pro USB". It works pretty much out of the box, you just need to build snd-usb-audio module into the kernel (3.0.4 that is). Sadly it's a pretty stupid device: It has no hardware mixer. So alsamixer won't give me a volume control bar, unless I set one up through a complicated asound.conf soft mixer. But I don't really need that anyway.
So, back on topic, the new USB soundcard now is connected, but for some reason herrie doesn't work well with it. Sound is horrible and stuttering. Maybe I'll file a bug...
So it was time to look for other players. Gentoo has media-sound/moc. Turns out it was a good idea to try something new. First of all, moc works nicely with the USB soundcard. It might have something to do with the architecture. Moc is multithreaded and has a seperate thread for the playback and for the user interface.
This is how moc looks on my console:
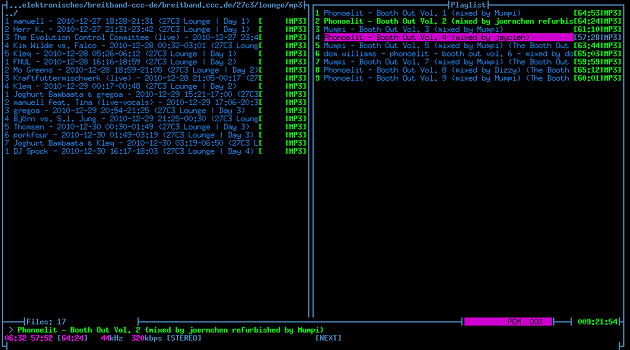
Besides beeing a functional console music player, moc also has some cool features:
- can run in the background (without screen)
- is themable
- can seek pretty fast
- has it's own soft mixer for volume
- supports a good number of audio formats
So if you are looking for a good console audio player, you can give it a try.
Most native code / C++ software vendors nowadays have implemented coredumps for their software. "coredump" is a term from computer history, when main memory was magnetic core memory. A coredump is the frozen and stored state of a process at the time of a CPU exception (aka crash). It can be loaded in the debugger and analyzed (given you have the binary and the debugging symbols). On Linux it must be enabled in the kernel and by the system administrator via rlimit. On Windows, developers can use structured exception handling to catch a deadly exception and execute some little piece of code which then calls a Windows API function which creates a coredump.
When a crash in a production environment should happen, you then get a coredump stored on disk and can receive that from you customer. While crashes should not happen at all, when they happen, coredumps are extremely helpful.
Now recently I got a very special coredump on my desk. Here is what happened (Intel assembly this time, as it's on Windows).
The exception handler has catched an exception: "Unhandled exception at 0x57dff720 in SomeBinary.exe.dmp: 0xC0000005: Access violation."
Hmm, not much to see here, but the debugger put's us at the position of the crash:
.
.
.
004D4AFF mov edx,dword ptr [ecx]
004D4B01 push eax
004D4B02 mov eax,dword ptr [edx]
004D4B04 call eax
-- baaammmm, crash here --
.
.
.
With registers:
EAX = 57DFF720 //indeed, thats what happened
ECX = 7843BD48
EDX = 7891F8D0
EIP = 004D4B06 //crash here
Hmm, what could that be? When something like that happens during development, you most likely have used an old invalid pointer or committed a crime of pointer juggling. When it happens during production, it's probably something terrible like a heap corruption or a race condition which you didn't find during development. The fact that there were something like a hundred other threads open in this coredump, didn't make matters betters. I feared for the worst. So the first thing I did was to find the bigger picture of where exactly I am in the code. The problem with production assembly code is, that it's optimized and has little to do with the source code anymore. Especially C++ templates and inlining make reading assembly hard, even if you have the sources.
From the debugger line it was clear that this is in the return section of a method call when the compiler starts calling destructors. Something like this:
void SomeClass::someMethod(...) {
boost::intrusive_ptr<SomeBaseClass> foo(new SomeContreteClass());
.
.
.
// -- crash here, right before the return --
return;
}
A little more assembler context made it clear, that the final call instruction
should have been the invocation of the virtual destructor from the SomeConcreteClass
object in the heap.
foo is an intrusively reference counted pointer on the dynamically allocated object.
Intrusively counting the reference means, that the object itself contains
the counter and carries it, even when it is degraded to just a raw pointer.
Because SomeConcreteClass was derived from SomeBaseClass and polymorphic, the
compiler needs to find out the correct destructor uppon destruction of
foo. With that knowledge I could start looking at the heap.
ECX seemed to contain the address of the object in the heap. Now I had a look
at the memory:
@ECX:
0x7843BD48 | 0082cf54 00000001 ...
That looks like a vtable pointer followed by the refcount which was down to 1. Maybe the vtable pointer was bad? So I followed the vtable pointer.
0x0082CF54 | 004355b0 0042c5d0 0042c5e0 ...
Well, this doesn't help much, but the disassembly looked sane and the debugger had a symbol for the address:
SomeConcreteClass::`vftable':
0082CF54 mov al,55h //whatever, I don't care
0082CF56 inc ebx //but it looks OK
0082CF57 add al,dl
So why could that fail?
Just look what happend. The first mov instruction at 0x004D4AFF is supposed
to load the address of the vtable into EDX which should be 0x0082cf54.
But EDX has a totally different value (0x7891F8D0).
And that's the end of the story: the CPU must have failed on us. I repeat: The CPU has failed.
Either through broken RAM (most likely) or something like a TLB bug. I just loved finding that one ... and telling the customer to fix his hardware :)
You know, those web browsers with ssl support ... they have a reason why they basically ignore any OCSP/CRL errors.
Today I stumbled uppon a root certificate of a not-so-small international CA.
Opinions differ, but generally CA roots should also be revokable and thus have an OCSP
responder configured. Said certificate is one of the better roots and thus
has a responder https://ocsp.some-ca.com set.
Now when you contact this responder something unexpected happens:
~ $ openssl s_client -host ocsp.some-ca.com -port 443
CONNECTED(00000003)
3125948630696:error:140770FC:SSL routines:\
SSL23_GET_SERVER_HELLO:\
unknown protocol:s23_clnt.c:683:
...
hmm ... something went wrong.
tcpdump + wireshark shed some light on the problem: SYN, SYN-ACK, ACK ... tcp up, that's good ... now we send the SSL Client Hello.
What we didn't expect was the reply from the server. A blatant (unencrypted):
HTTP/1.1 400 Bad Request
Server: Apache-Coyote/1.1
Transfer-Encoding: chunked
Date: Thu, 03 Nov 2011 17:45:54 GMT
Connection: close
Indeed, openssl is right: that doesn't look like an SSL handshake. It looks more like a slap with a large trout.